
Содержание:
Индексация сайта — это необходимый и сложный процесс, требующий достаточно продолжительного времени. Однако, не все документы на сайтах, созданных при помощи популярных движков, должны быть проиндексированы, и появиться в выдаче. Решением этой проблемы может стать robots.txt.
Что такое и для чего создается файл robots.txt
Robots.txt представляет собой файл в текстовом формате. Его основная задача состоит в создании ограничений доступа к разделам и страницам ресурса для поисковых ботов. Ограничение доступа позволяет скрыть эти разделы и страницы от индексации, и, соответственно, от чужих глаз тоже.
Данный файл следует располагать в корневой папке ресурса. При наличии у сайта поддоменов, для каждого из них формируется отдельный файл. Создание файла robots.txt позволит вам:
- уберечь от индексации административные файлы сайта, которые могут содержать пароли и другую конфиденциальную информацию;
- ускорить индексацию поисковыми ботами, прописав путь к карте сайта, содержащей все необходимые для индексации адреса страниц сайта;
- запрет индексации способствует снижению излишней нагрузки на сервер, и поможет избежать риска многократного дублирования сведений, к чему негативно относятся все ПС.
Также с помощью файла robots.txt можно запретить к индексации сайт целиком. Такое решение может быть актуально на стадии разработки ресурса. К примеру, если разделы то создаются, то удаляются, а страницы переносятся из одной категории в другую.
Синтаксис файла robots.txt
Файл, о котором идет речь в этой статье, имеет жесткие правила синтаксиса в сочетании простой и понятной структурой. Набирать его следует в кодировке ANSI. Структура robots.txt представляет собой один и более блоков (для разных роботов) с набором директив. Между блоками оставляется пустая строчка. Не допустимы: вступительные директивы, символы между блоками (помимо перевода строк) и лишние символы в директивах.
Что касается комментариев, то они следуют за символом # и могут продолжаться до окончания текущей строчки. Все эти символы, от знака # определяются как комментарии, поисковой бот их игнорирует.
User-agent: Yandex Disallow: /css #вот тут комментарий #здесь тоже комментарий, оба они будут проигнорированы Disallow: /image
Каждый блок следует начинать директивой User-agent. Она содержит значение конкретного поискового бота. Вот пример директивы для основного робота Яндекса, и обращающейся ко всем поисковым ботам без исключения:
User-agent: YandexBot
и
User-agent: *
Самыми востребованными операторами в robots.txt можно назвать Disallow и Allow. Первый дает возможность запретить, а второй — разрешить индексацию. Подробнее об этом можно прочесть пункте №4
Как упоминалось в пункте №1, вы можете внести путь к карте сайта в файл robots.txt при помощи соответствующей директивы — Sitemap. Анализируя ее, поисковой бот обнаружит наличие файла sitemap xml. Это будет учитываться им при последующих посещениях вашего ресурса. Выглядит это так:
User-agent: * Disallow: /avatars Sitemap: http://www.имявашегоресурса.ru/dir/sitemap1.xml
Следующую директиву воспринимают далеко не все ПС, называется она Host. Из популярных поисковик ее может распознать лишь Яндекс. Такая директива поможет обозначить основное зеркало вашего ресурса и может использовать только один раз. Указывать ее нужно после предыдущих директив. В случае когда сайт доступен по более, чем одному домену, например, example.ru или .com, и, допустим, что у основного зеркала имеется префикс www, то код будет следующим:
User-agent: Yandex Disallow: /avatars Host: www.example.com
Чтобы определить для бота минимальный отрезок времени, через который необходимо посещать ресурс, используйте директиву Crawl-delay. Это способствует снижению нагрузки на сервер:
User-agent: * Disallow: /avatars Crawl-delay: 6 — также некоторые роботы понимают нецелые значения, например, 6,5
Не обязательная, но в целом полезная директива Clean-param пригодится при наличии двух и более одинаковых страниц с немного отличающимися URL. Здесь можно привести параметр, предписывающий поисковому боту, учитывать разные значения, как один и тот же адрес. Помните, что эту директиву тоже способен распознать лишь Яндекс. «Схематично» следует писать так:
Clean-param: parm1[&parm2&parm3&parm4&..&parmn] [Путь]
Как проверить файл robots.txt
Создать такой файл — это только часть дела. Его проверка является обязательным условием для того, чтобы уберечься от ошибок при индексации. Поэтому после составления и помещения robots.txt в корень своего ресурса, стоит приступить к его проверке в ПС.
Войдите в аккаунт Яндекс Вебмастер и через «Настройки индексирования» в «анализ robots.txt». Загружаете файл с сайта специальной кнопкой и видите окошко с его содержимым.

Нажав «добавить», в выпадающем окне можно ввести несколько адресов страниц вашего ресурса для проверки. Вводите туда несколько разрешенных и запрещенных URL.
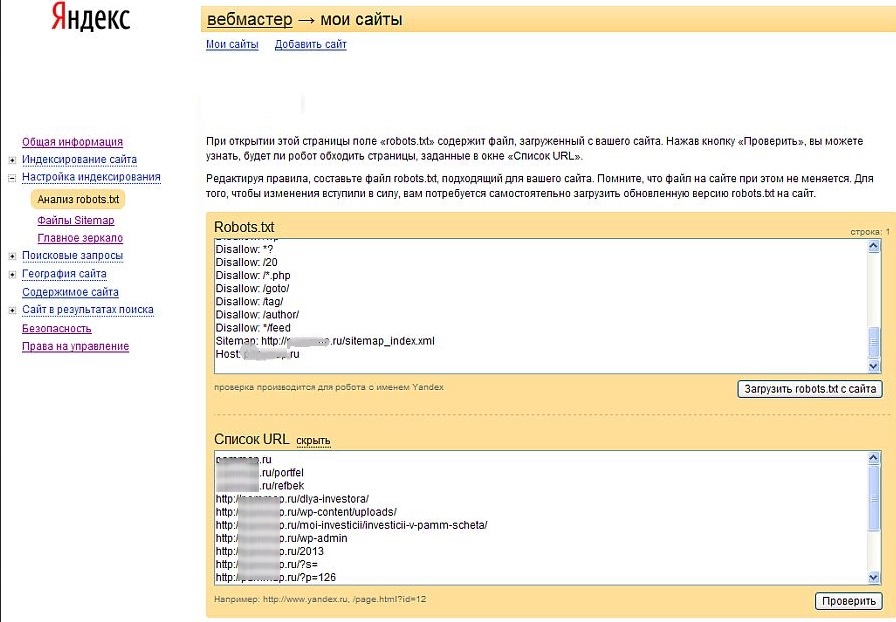
После нажатия «Проверить» Яндекс выдаст результаты. По ним можно судить, насколько успешно прошел проверку ваш файл. Внимательно просмотрите: все ли запрещено, что должно быть запрещено, и наоборот.
Проверка в ПС Google не имеет принципиальных отличий и практически идентична с проверкой в Яндексе. Войдите в свой аккаунт Google Вебмастерс и в меню «Сканирование» (слева) выберите «Инструмент проверки файла robots.txt»:
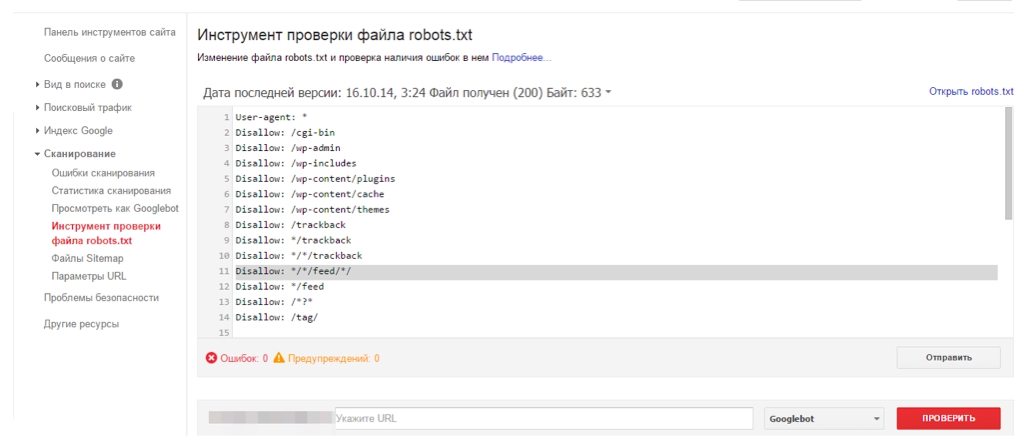
Как запретить и разрешить индексацию в robots.txt
Самая распространенная в robots.txt директива Disallow. Она дает возможность запретить сайт или какую-либо его часть к индексации. Так, чтобы не допустить весь сайт к индексации в Яндексе пишем:
User-agent: Yandex Disallow: /
Стоит упомянуть о символах * и $. Первый из них поисковыми ботами приписывается указанному пути по умолчанию и свидетельствует о неограниченно количестве любых символов (к примеру, вводим dir*, а запрещены будут еще и dir1, diroooooo и пр.). Т. е. следующие предписания не имеют отличий:
Disallow: /css Disallow: /css*
Чтобы не допустить такого «додумывания» по умолчанию, поставьте в конце строки знак $:
User-agent: * Disallow: /dir$
Директива Allow обладает похожим синтаксисом с предыдущей директивой. При этом является разрешительной. Чтобы запретить всем ботам индексировать сайт полностью, кроме того, что начинается с subname (эта часть разрешается для индексации), нужно написать следующее:
User-agent: * Allow: /subname Disallow: /
Помните, что приоритет при одновременном применении этих двух директив, больше не определяется их последовательностью. Алгоритм таков, что приоритет будет иметь то указание, которое имеет максимальную длину префикса URL. А при наличии одинаковой длины префикса у обеих директив, приоритет получает Allow.
Что лучше применять для запрета к индексации: robots.txt или noindex
Для исключения попадания страницы или документа в индекс можно использовать не только файл robots.txt, но и noindex. Это два разных метода, которые хороши для применения каждый по-своему. Если нужно избежать индексации страницы, применяйте noindex в мета-теге robots. В хэдер страницы внесите следующие изменения:
<meta name=”robots” content=”noindex, follow”>
Таким образом вы:
- исключите страницу из индекса при ближайшем посещении бота ПС;
- получите передачу ссылочного веса страницы.
Файл robots.txt идеально подойдет, если нужно запретить к индексации:
- файлы с административными сведениями;
- итоги поиска по ресурсу;
- странички с профилями, а также восстановлением паролей, регистрацией и авторизацией.
Как создать файл robots.txt для WordPress, Joomla, Dle, Drupal
Кроме ручного способа формирования данного файла, вы можете воспользоваться специализированными плагинами. Для каждого движка следует применять отдельный плагин. Приведем примеры для всех популярных движков.
Для WordPress рекомендую применять плагин PC Robots.txt. Он весьма удобен в использовании. Вы получаете возможность изменять информацию, внесенную в файл, прямо через панель управления вашим ресурсом.
Для Joomla роботс есть в комплекте движка. Выставленные по умолчанию параметры позволяют закрыть главные служебные директории. При этом они делают недоступными для внесения в индекс картинки.
Достаточно удобным и элегантным решением для такого движка, как Dle, является модуль DonBot. Он дает возможность вносить все необходимые правила. Также этот модуль предлагает несколько настроек для получения лучшего результата.
Движок Drupal, как и Joomla обладает собственным стандартным robots. В нем по умолчанию защищены от индексации все стандартные директории с файлами движка (но не контента). Но для улучшения результатов, стоит пересмотреть стандартны настройки и внести изменения «под себя».
Рекомендую:
Если хотите получить перспективную профессию или освоить новый навык (будь то SEO, HTML, веб-программирование или даже мобильная разработка), то посмотрите ТОП-3 лучших онлайн школ:
- Нетология — одна из старейших школ интернет-профессий. Основные направления — маркетинг, управление, дизайн и программирование;
- GeekBrains — специализируется, в первую очередь, на обучении программистов. После интеграции в Mail Group появились и другие профессии;
- SkillBox — наиболее молодая из 3-х перечисленных школ, но обладает наибольшим ассортиментом специальностей. Если услышали о какой-либо экзотической профессии, то наверняка этому уже обучают в Skillbox.
Эти школы выдают дипломы и помогают с трудоустройством, а если вам нужно просто научиться что-то делать для себя больше как хобби, то рекомендую начать с бесплатных курсов, они позволят получить общее представление о профессии и первый практический опыт.
 Сообщить об ошибке
Сообщить об ошибке



А вот как разрешить индексацию неканонических страниц в robots.txt, если нет возможности избавится от атрибута rel "canonical" в коде страниц??? Есть ли решение?
Если специфическая CMS, поставьте задачу программисту.